
The SMeL Test: A simple benchmark for media literacy in language models
A minimal benchmark showing that even strong language models struggle to filter untrustworthy and fictional information from context.

I’m a fifth-year PhD student in Computer Science at Harvard University. I’m a member of the Machine Learning Foundations Group, advised by Boaz Barak, and supported by a graduate fellowship from Harvard’s Kempner Institute.
My primary research interest at the moment is uncertainty quantification, especially for large language models in realistic, unconstrained settings. Highlights include a new approach for automatically generating uncertainty labels in unconstrained text at scale, a rigorous framework for evaluating and improving uncertainty decompositions, and a general technique for enhancing uncertainty estimates for long-form LLM generations. Along the way, I've also worked on enabling real-time interactivity in LLMs and a benchmark measuring their ability to screen out untrustworthy information.
Previously, I interned at Meta in 2025 and Apple in 2024. I earned a B.A. in Computer Science and History (2020) and an M.S. in Computer Science (2021) from Columbia, where I worked with Mohammed AlQuraishi on protein structure prediction and led the development of OpenFold.
A minimal benchmark showing that even strong language models struggle to filter untrustworthy and fictional information from context.

Higher-order calibration provides a necessary and sufficient condition for uncertainty decompositions with real-world semantics.
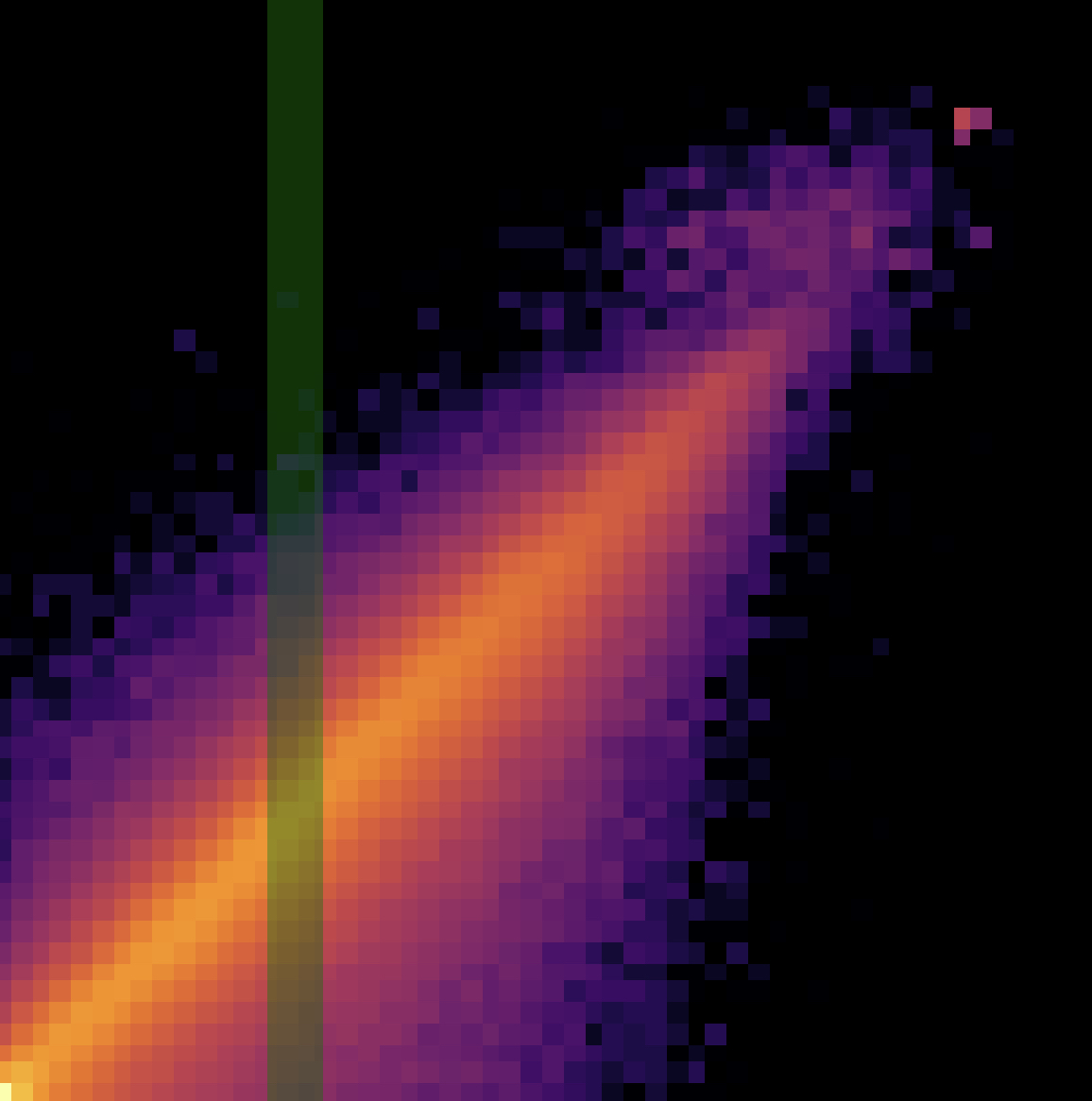
Small linear probes can predict when much larger language models will be confident—even out of distribution.
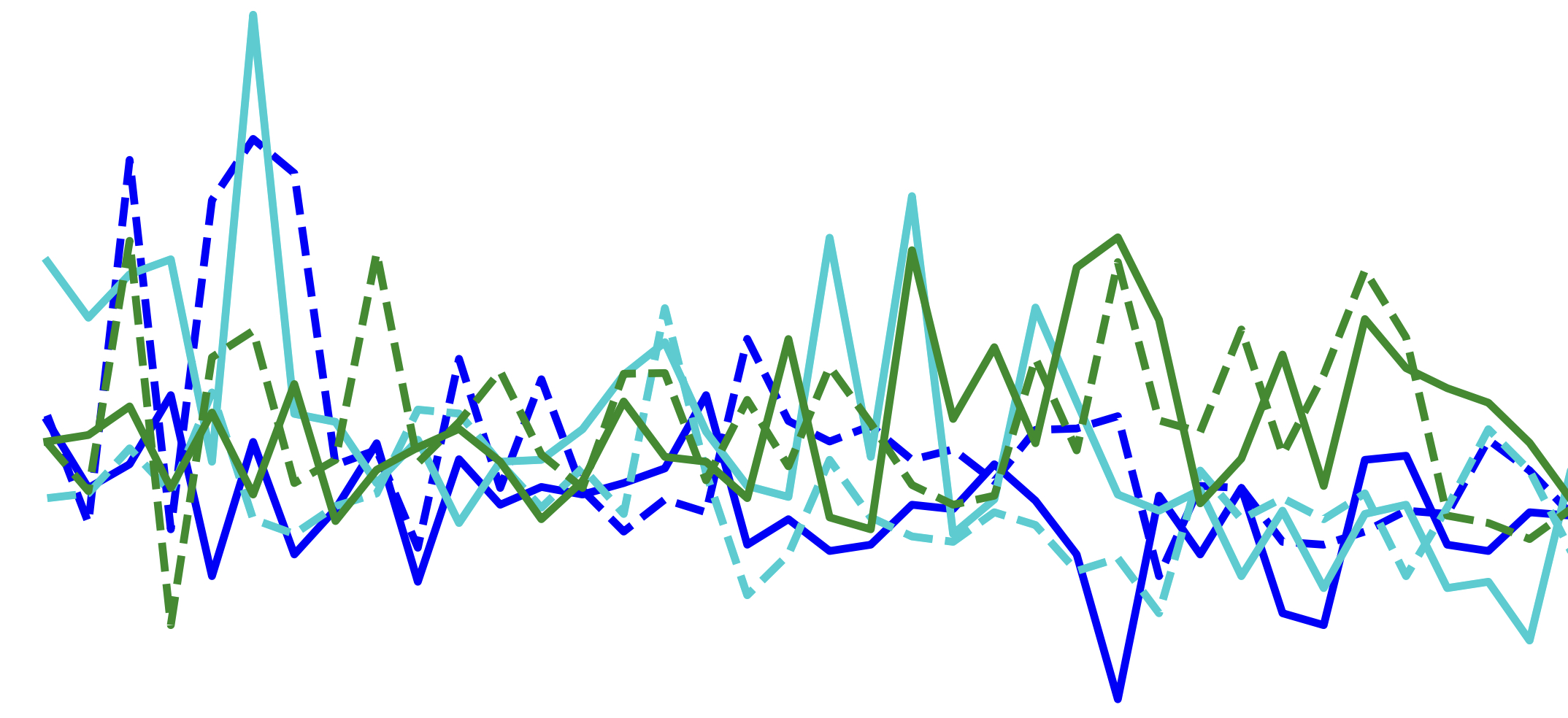
Language models trained on timed, diarized transcripts can support genuinely real-time text and spoken interaction.

The first trainable, open-source reproduction of AlphaFold2—and a platform for studying how the model learns to fold proteins.
Gustaf Ahdritz, Nazim Bouatta, Sachin Kadyan, Lukas Jarosch, Daniel Berenberg, Ian Fisk, et al.
Luke Bailey*, Gustaf Ahdritz*, Anat Kleiman*, Siddharth Swaroop, Finale Doshi-Velez, Weiwei Pan
Ratul Chowdhury*, Nazim Bouatta*, Surojit Biswas*, Christina Floristean*, Anant Kharkar, Gustaf Ahdritz, et al.
* Equal contribution.